信息论基础
2023-04-27 ·
1174字 ·
6 min read
🏷️
Article
熵 Entropy 的定义
离散型随机变量 (字母表为 ,概率函数 ),entropy 熵定义为:
- ( 趋近于 0, 趋近于 0 )
- 当 是在 服从均匀分布时,
- - 算法/定义中的对数如果以 为底,熵记作 - 以 2 为底,单位为 bits - 以自然常数 e 为底,单位为 nats
(衡量信息量大小,不确定性大小)
例子
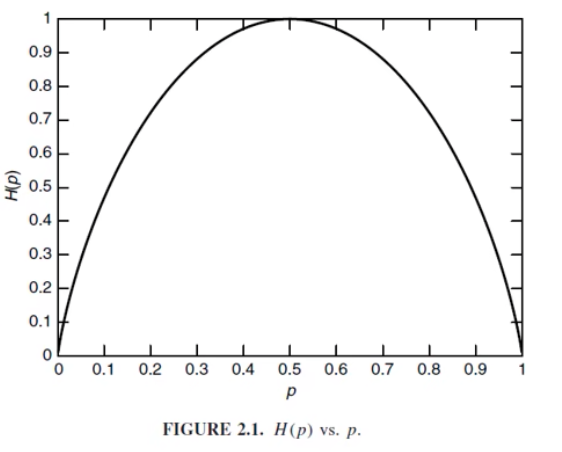
二进制熵函数
系统的熵: ,关系如下:
性质

说明:
- 凹函数(凹向下)的性质 [1]
- 这里的 取值都是
- 当且仅当,均匀分布取到最大熵 (均匀分布最大化离散熵)
根据熵的定义,它只由概率分布确定,根据概率分布,可以得到联合熵、条件熵,链式法则。
概率统计中的法则
链式法则:
贝叶斯规则:
联合熵 Joint Entropy

条件熵 Conditional Entropy

- 条件熵 是,在 上定义的熵,对 x 取加权平均;或者直接根据期望计算。
- 根据期望计算时,使用的是
例子

- 条件熵不可交换变量的位置
-
- 可以根据定义的期望公式证明,参考下面的链式法则
- 可以从信息的不确定性来理解
链式法则

零熵 Zero Entropy

说明:如果熵 ,对于离散变量 ,其概率分布只有一个取值
- 由 ,根据它的定义容易得到;
- 由 ,容易知道 Y 在 下只有一个确定的取值;
- Y 是 X 的函数。
相对熵 Relative Entropy
相对熵:用来度量两个概率分布的距离
相对熵 (Kullback-Leibler(KL)距离) ,在字母表 上的两个概率分布函数 的 KL 距离定义为:
说明:
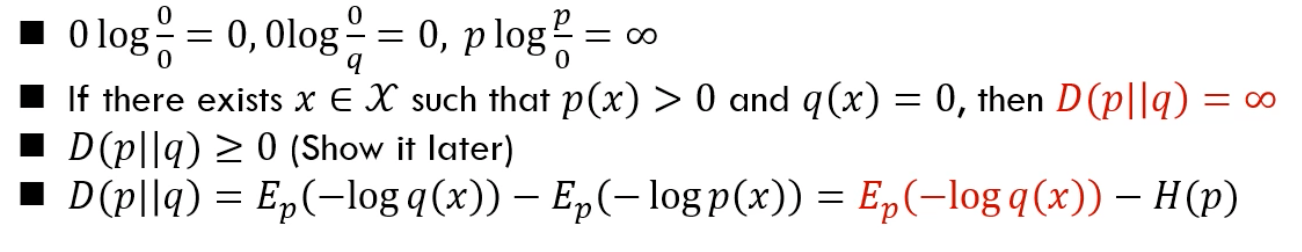
Not Metric
相对熵不是一种 Metric 测度

互信息 Mutual Information
互信息,用来衡量两个随机变量的关联程度(相互拥有的信息量),使用相对熵【p(x,y) 与 p(x)p(y)】来定义:

- 互信息的两个变量可以交换位置
- 两个相互独立的互信息为 0;同一个变量的互信息为它的熵
- 互信息 中,使用分号
;分隔两个变量
Venn 图
使用 Venn 图理解多个信息量的度量
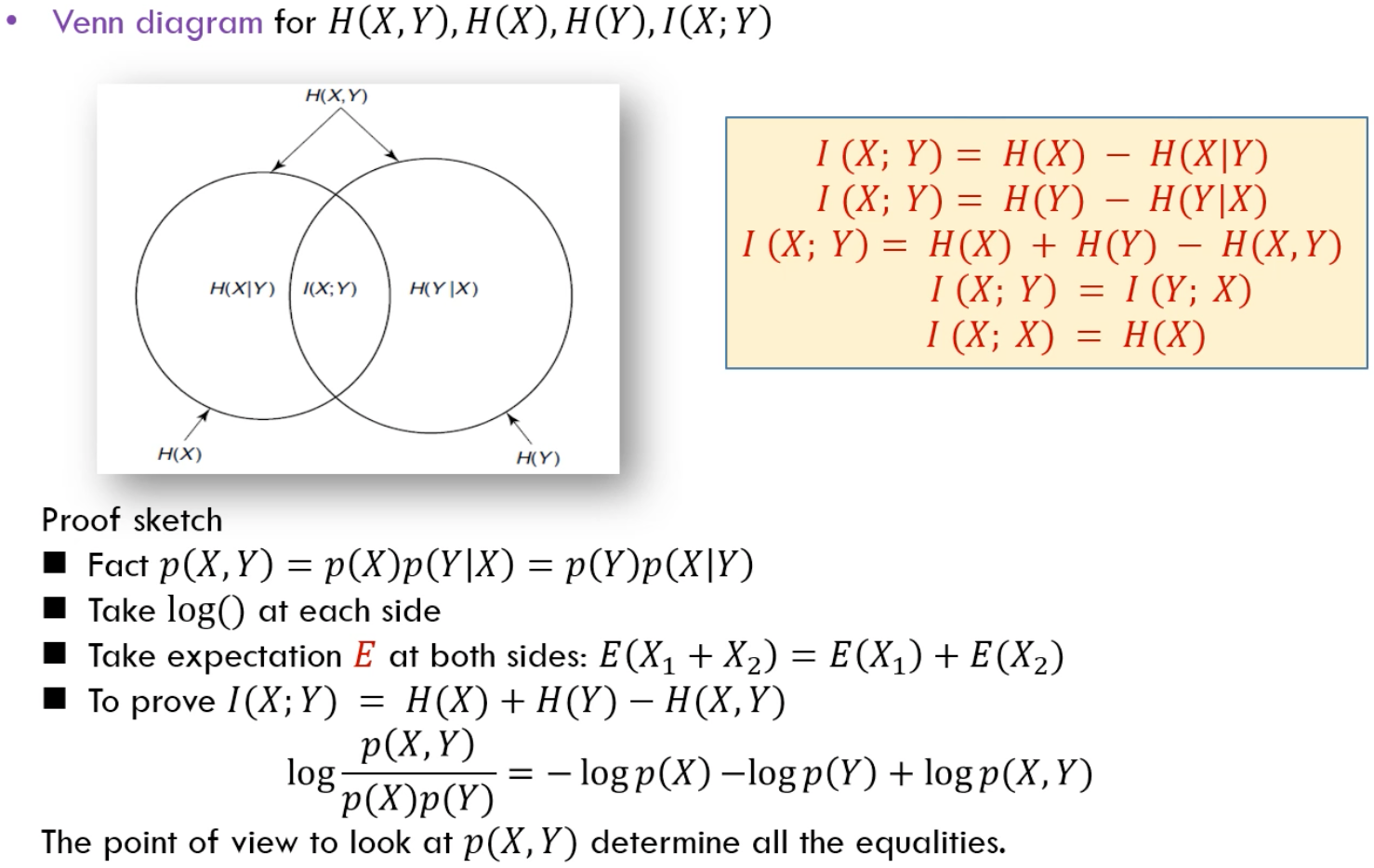
多个变量的链式法则

条件互信息
为了描述在变量 给定条件下,变量 的互信息量(符号中 是整体,表示条件 )

条件相对熵
条件相对熵和相对熵的链式法则:

链接
本文已被阅读
0
次,该数据仅供参考
欢迎任何与文章内容相关并保持尊重的评论😊 !