Simple Regenerating Codes: Network Coding for Cloud Storage
简单再生码,能够以较低成本简单快速地精确修复,编码效率接近
Ⅰ. INTRODUCTION
编码的分布式存储系统中一个中心问题是在故障发生时保持系统编码表示,即维持系统的冗余。
网络编码:修复纠删码系统中的节点故障需要编码分组(coded packets)的网络内(in-network)组合。
在研究精确修复问题中,有几个指标可以优化:修复期间从现有磁盘读取的总信息量、网络中通信的总信息量(修复带宽)或每次修复所需访问的磁盘总数。
Ⅱ. SIMPLE REGENERATING CODES
A. 编码构造
将文件 ,大小为 ,划分为 2 部分 。编码过程分为两步:
- 编码过程
通过一个 的 MDS 编码将文件的两个部分(即 )分别编码(因为每一个部分都有 个符号),记编码后编码块分别为长度为 的向量 和 :
其中 是 MDS 码生成矩阵,其最大距离性质保证了任意 或 的 个编码块都可以分别重建 或 ;最后通过异或生成 :
上述的编码过程一共产生 个编码块(符号)。
- 块放置策略
目的:将 个编码块放置到 个节点,则每个节点存储 3 个编码块。
方法:每个节点分别存储来自 的一个编码块,要求 3 个编码块下标都互不相同。对于 都可以采用如下的循环放置来实现:

B. 纠删弹性和码率
可以容忍任意的 个故障,从两个分别的 MDS 编码过程得到。
的编码效率(space efficiency) 等于有用的存储信息总量与存储数据总量之比:
并且上界是 , 固定时,。
C. 修复丢失块
由于丢失的每个块与存储在 2 个节点中的另外 2 个编码块为同一个索引,因此 SRC 能够轻松修复单个丢失的编码块或单个节点故障,通过通信这两个存活节点,可以通过简单的异或操作修复丢失的块。
修复单节点故障需要 2 倍丢失数据(6 个块)的修复带宽和磁盘读取,需要访问 个磁盘。
(4,2)-SRC 举例
举例 ,原始的数据对象划分为 ,分为 2 组,将 编码成 ;将 编码成 ,最后通过异或得到 ,过程如下:

Ⅲ. SIMULATIONS
使用云存储模拟器将所提出 码与 Replication 和 Reed-Solomon 码进行了比较。
主要的实验分析:
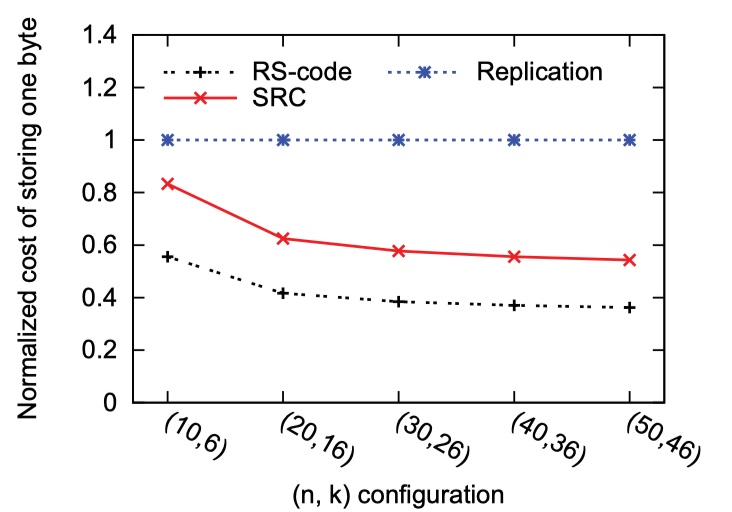
存储开销分析
的存储开销对比:
修复性能
测量修复故障节点时的吞吐量

- 3-副本的修复性能最好,其次是 SRC,而 RS 码的修复性能最差。(考虑修复需要访问的数据量)
- 在不同的 下,SRC 的修复性能保持不变,但随着 n 的增加,RS 码的修复性能变差;其主要优点之一:修复性能独立于 。
- 此外,SRC 的修复吞吐量约为 500MB/s,约为 3-副本性能的 64%。
数据可靠性分析
使用一个简单的马尔可夫模型[3]来估计可靠性。为简单起见,故障仅发生在磁盘上,假定故障没有相关性。

- SRCs 的可靠性远远高于 3-副本()。即使对于高码率(50,46),SRC 也比 3-副本可靠几个数量级。受益于 SRC 的高修复速度。
- RS 码呈现明显不同趋势。虽然(10,6)和(20,16)的可靠性高于 3-副本,但随着(n,k)的增长,RS 码的可靠性大大降低。因为它们的修复性能随着 k 的增加而迅速下降。
Ⅳ. CONCLUSIONS
- 提出了结构简单的 SRC,主要特点:
- 可以容许任意 个节点故障,是 MDS 编码;
- 码率(编码效率)为 ,可以无限接近
- 修复单个节点很高效,得益于特定的块放置策略和编码过程中第二步的异或编码,可以实现精确修复;修复单个节点最多访问 个磁盘(节点),修复带宽和访问的数据量都是
丢失数据的2倍。 - 总体上是一个结构简单,易于实现的一类编码。
- 主要思想:两个 MDS 预编码用于针对任何 故障提供可靠性,而应用于 MDS 编码分组之上的 XOR 在单节点故障发生时提供有效精确修复。
附录(折衷)
上述将文件 ,大小为 ,划分为 2 部分。一般 ,将数据分为 ,划分为 个部分,编码策略一样,共生成 个编码块,每个节点存储 个块。分析:
- 编码效率()
编码效率是 MDS 码的
- 每个节点的存储()
- 单个节点的修复带宽()
- 单节点修复的磁盘访问个数()
参考论文
- A. G. Dimakis, P. G. Godfrey, Y. Wu, M. J. Wainwright, and K. Ramchandran, “Network coding for distributed storage systems,” in IEEE Trans. on Inform. Theory, vol. 56, pp. 4539 – 4551, Sep. 2010.
- A. G. Dimakis, K. Ramchandran, Y. Wu, and C. Suh, “A survey on network codes for distributed storage,” in IEEE Proceedings, vol. 99, pp. 476 – 489, Mar. 2011.
- D. Ford, F. Labelle, F. I. Popovici, M. Stokely, V.-A. T. L. Barroso, C. Grimes, and S. Quinlan, “Availability in globally distributed storage systems,” in OSDI ’10: Proc. of the 9th Usenix Symposium on Operating Systems Design and Implementation, 2010.
本文链接: Simple Regenerating Codes: Network Coding for Cloud Storage
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
发布日期: 2021-04-20
最新构建: 2025-05-16
欢迎任何与文章内容相关并保持尊重的评论😊 !